В Comms Multilingual мы очень заинтересованы в последних разработках в области оценки и сертификации. В связи с этим мы просим лидеров индустрии мысли предоставить гостевой вклад в наш блог, который, как мы надеемся, будет интересен нашему сообществу. 
Наш первый автор - доктор Джой Мэтьюз-Лопес. Доктор Мэтьюз-Лопес является старшим психометриком в области профессионального тестирования и адъюнкт-инструктором по математике в университете Огайо. Она пишет о тестовой адаптации и локализации с психометрической точки зрения.
Хотя перевод необходим и обычно является основным направлением в проекте адаптации / локализации теста, идеальный перевод может быть недостаточным для получения эквивалентного инструмента оценки или сопоставимых результатов. Причина этого проста: перевод ≠ адаптация.
Один из моих любимых примеров, демонстрирующих разницу между переводом и адаптацией, взят из экспериментальной работы, с которой я помог много лет назад. В этом примере тестовый вопрос представил испытуемым список функционально связанных слов. Длина списков может составлять от 4 до 8 слов. Испытуемым было предложено подумать о словах, а затем выбрать одну диаграмму из четырех возможных вариантов, которые наилучшим образом отображали слова в логическом порядке убывания.
В этом случае исходным языком был английский, а целевым языком был испанский. Английская версия этого предмета была опробована в Соединенных Штатах с англоговорящими старшеклассниками. Предмет был переведен на испанский язык, а затем был опробован в Мексике с испаноязычными учениками старших классов. Список слов этого конкретного вопроса содержал пять слов: виноград, желе, сок, завтрак и лозы. Этот список слов был переведен вперед, а затем обратно переведен с английского на испанский, а затем обратно на английский. Группа экспертов по предмету на двух языках рассмотрела и одобрила процесс перевода и окончательный выбор слов.
Английская версия предмета выглядела так (нажмите на картинку для увеличения). Ключ был вариант А.
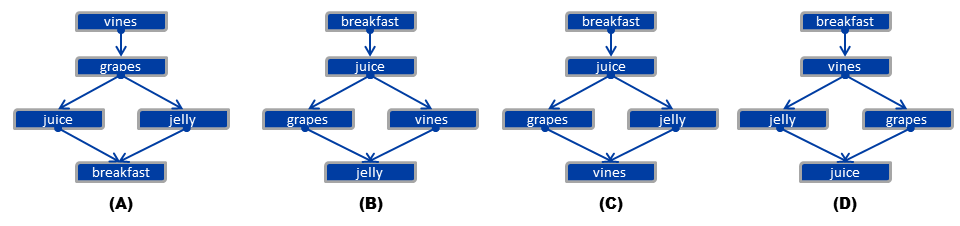
Переведенная версия предмета выглядела так:
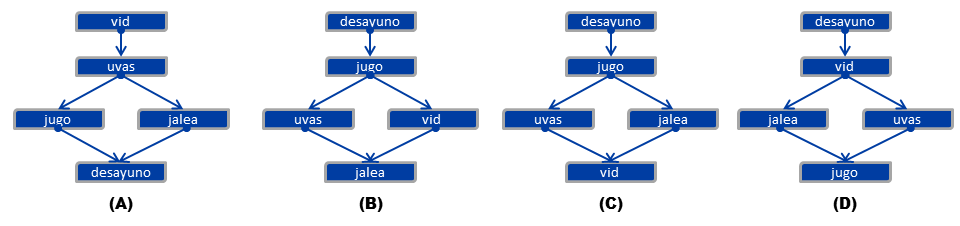
Опять же, ключом был вариант А. Однако при анализе данных классический индекс сложности (значение p) английской версии составлял 0,80, а значение p переведенного элемента составляло только 0,25.
Первой реакцией сотрудников Контента была проверка целостности перевода. Действительно, сок = jugo, завтрак = desayuno, виноград = uvas, лоза = vid, желе = jalea. Так что пошло не так? Как «идентичные» предметы могут работать так по-разному? Эквивалентность населения не была проблемой, так что же повлияло на сложность предмета?
Чтобы ответить на эти вопросы, в Мексике был созван комитет экспертов по двуязычным предметам бикультуры. Этот пункт, наряду с несколькими другими, которые вели себя не так, как ожидалось, был представлен на рассмотрение группы. В короткие сроки комитет указал на проблему: виноградный сок не является типичным напитком для завтрака в нашем целевом районе Мексики. Апельсиновый сок был.
Затем предмет был адаптирован к целевой группе, и список слов стал соком, завтраком, апельсинами, апельсиновыми деревьями и мармеладом, и проблема была решена удовлетворительно.
Адаптированная версия нашего предмета выглядела так:
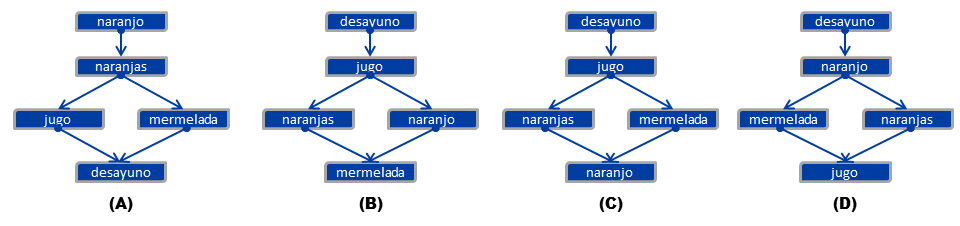
После второго раунда пилотирования значение p этого адаптированного предмета составило 0,80, то же самое, что и исходный предмет на английском языке. Перевод был критически важен в процессе адаптации, и, несмотря на то, что перевод был безупречным, он не соответствовал культурным условиям. Перевод может быть необходим, но он не обязательно достаточен в тестовой адаптации.
Так что пошло не так?Как «идентичные» предметы могут работать так по-разному?
Эквивалентность населения не была проблемой, так что же повлияло на сложность предмета?